|
|
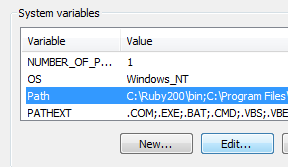
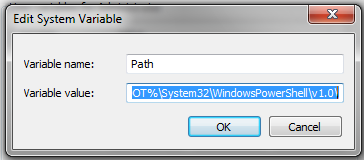
Bewerken van gegevens met OsmosisOsmosis is een krachtig gereedschap voor de opdrachtregel voor het bewerken en verwerken van ruwe gegevens voor .osm. Het wordt vaak gebruikt voor het verwerken van grote gegevensbestanden, voor het splitsen van bestanden van OSM in kleinere stukken, en voor het toepassen van een wijzigingenset om een bestaand bestand bij te werken. Er zijn veel fantastische functies beschikbaar met Osmosis, en u kunt over elk daarvan in detail lezen op de Wiki. Echter, veel van de functies zijn nogal complex en moeilijk te begrijpen, in het bijzonder als u net begint met programma’s voor de opdrachtregel en OpenStreetMap. Dit hoofdstuk dient als introductie voor Osmosis, het installeren op Windows, en beginnen met een basisopdracht voor Osmosis. Osmosis installerenNet zoals met osm2pgsql in het vorige hoofdstuk, dienen we osmosis te downloaden en in te stellen zodat we het vanaf de opdrachtregel kunnen uitvoeren. Het proces hiervoor is zeer soortgelijk aan dat van osm2pgsql. U zult ook enige ruwe gegevens van OSM nodig hebben om mee te werken. Als u de voorbeelden in dit hoofdstuk wilt volgen, download ons voorbeeldbestand dan hier. U kunt ook een bestand met ruwe gegeven van uw keuze gebruiken. Volg deze stappen voor het downloaden en voorbereiden van Osmosis:
Gegevens filterenOsmosis zou nu correct vanaf de opdrachtregel moeten werken. We dienen de werkmap te wijzigen naar de plaats waar we het bestand sample_osmosis.osm.pbf hebben geplaatst om bewerkingen te kunnen laten uitvoeren op ons bestand met gegevens. We hebben, om dingen eenvoudig te houden, dit bestand geplaatst in de *map C:*.
Laten we nu onze eerste opdracht voor Osmosis leren. We zullen een opdracht uitvoeren die alle scholen uit ons grote bestand filtert. We dienen, om dit te kunnen doen, Osmosis een aantal dingen te vertellen. We moeten specificeren:
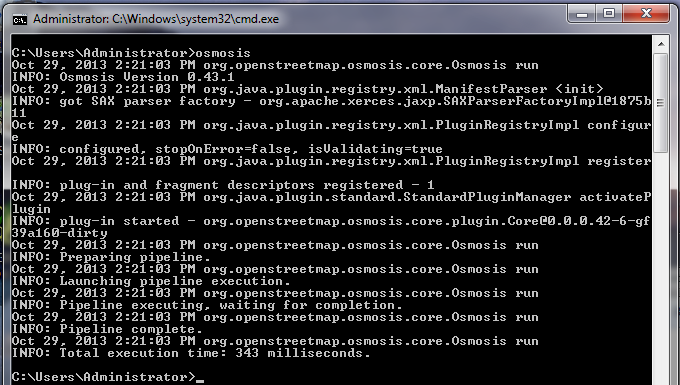
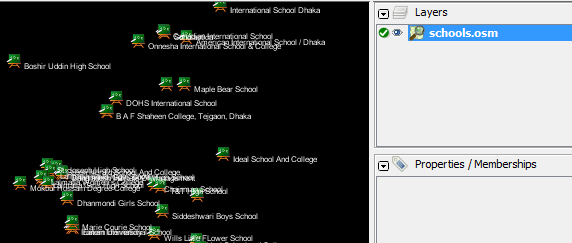
De opdracht die we uit zullen voeren is: Probeer deze opdracht uit te voeren op de opdrachtregel. Als het voltooid is zou u een nieuw bestand in uw map moeten zien, genaamd schools.osm. Als we het nieuwe bestand openen in JOSM, kunnen we zien dat alleen de scholen uit het voorbeeldbestand zijn gefilterd.
Laten we eens stukje voor stukje kijken naar de opdracht die we uitvoerden om te begrijpen hoe het allemaal werkt. Als eerste roepen we de naam van het programma aan. Vervolgens geven we het invoerbestand op. Onthoud dat dit bestand in een gecomprimeerde indeling is. –rbf is in feite een afkorting voor –read-pbf-fast. Osmosis begrijpt dat het bestand dat we na deze vlag toevoegen het bestand is waaruit we willen lezen. het volgende gedeelte van onze opdracht zegt –nkv keyValueList=”amenity.school”. U zou kunnen raden dat dit aangeeft dat osmosis alles uit zou moeten filteren dat de tag amenity=school heeft. –nkv is een afkorting voor –node-key-value. Deze opdracht geeft aan dat Osmosis alleen knopen met sleutels en waarden zou moeten uitfilteren die worden opgegeven in de volgende lijst. Aanvullende sets voor sleutels-waarden kunnen worden toegevoegd door er komma’s tussen te zetten. tenslotte geven we de naam en indeling van het uitvoerbestand op. We gebruiken de vlag -wx, wat een afkorting is voor –write-xml. Onthoud dat we ook –wb zouden kunnen gebruiken, wat het tegenovergestelde is van –rbf, als we de uitgevoerde gegevens ook in de indeling PBF zouden willen hebben. Voorwaarts gaanHet aantal verwerkingstaken die met Osmosis kunnen worden uitgevoerd is enorm, en om meer te leren is het het beste om te kijken naar de pagina Osmosis Detailed Usage op de wiki. Eén nuttige taak is in staat te zijn een groot ruw bestand van OSM op te delen in afzonderlijke delen, ofwel door rechthoeken op te geven of door bestanden met grenspolygonen te maken. U kunt een basis voor dit proces vinden op de pagina Osmosis Examples.
Was dit een goede handleiding?
Laat ons weten hoe we de handleidingen kunnen verbeteren!
|