|
|
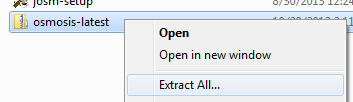
Manipulação de dados com OsmosisO Osmosis é uma poderosa ferramenta de linha de comandos para manipular e processar dados brutos .osm. É frequentemente utilizada para processar grandes ficheiros de dados, para dividir ficheiros OSM em partes mais pequenas e para aplicar um conjunto de alterações para atualizar um ficheiro existente. Há um grande número de funções disponíveis no Osmosis, e pode ler sobre cada uma delas em pormenor na wiki. No entanto, muitas das funções são bastante complexas e difíceis de compreender, particularmente se estiver a iniciar-se nos programas de linha de comandos e no OpenStreetMap. Este capítulo servirá para apresentar o Osmosis, instalá-lo no Windows e começar com um comando básico do Osmosis. Instalar o OsmosisTal como o osm2pgsql no capítulo anterior, teremos de descarregar e configurar o Osmosis para o podermos executar a partir da linha de comandos. O processo para isso será muito similar ao do osm2pgsql. Também vai precisar de alguns dados OSM em bruto para trabalhar. Se quiser seguir os exemplos deste capítulo, descarregue o nosso ficheiro de amostra aqui. Também pode utilizar um ficheiro de dados em bruto à sua escolha. Siga estes passos para descarregar e preparar o Osmosis:
Filtrar dadosO Osmosis deve estar agora a funcionar corretamente a partir da linha de comandos. Para executar operações no nosso ficheiro de dados, temos de mudar o diretório de trabalho para o local onde colocámos o ficheiro sample_osmosis.osm.pbf. Para simplificar as coisas, colocámos este ficheiro no *diretório C:*.
Agora vamos aprender o nosso primeiro comando Osmosis. Vamos executar um comando que filtra todas as escolas do nosso grande ficheiro. Para o fazer, precisamos de dizer ao Osmosis algumas coisas. Precisamos de especificar:
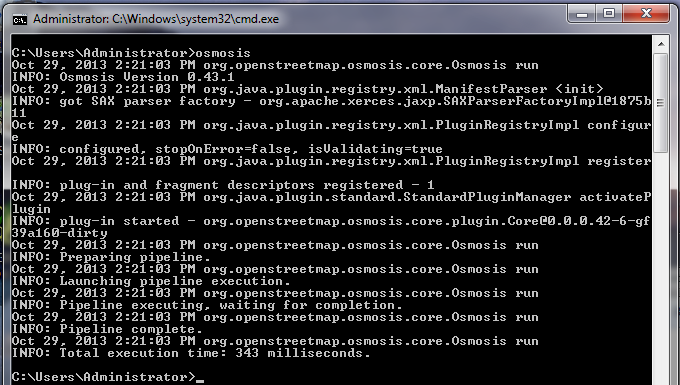
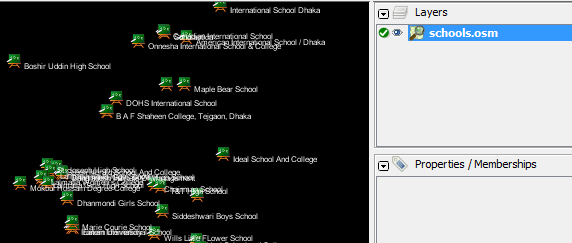
O comando que vamos executar é: Tente executar este comando na linha de comandos. Quando terminar, deverá ver um novo ficheiro no seu diretório, chamado schools.osm. Se abrirmos o novo ficheiro no JOSM, podemos ver que apenas as escolas foram filtradas do ficheiro de amostra.
Vamos dar uma olhadela ao comando que executámos, peça por peça, para perceber como tudo funciona. Primeiro, chamamos o nome do programa. Em seguida, fornecemos o ficheiro de entrada. Lembre-se que este ficheiro é um formato comprimido. –rbf é na verdade uma abreviação para –read-pbf-fast. O Osmosis entende que o ficheiro que fornecemos depois desta flag é o ficheiro a partir do qual queremos ler. A parte seguinte do nosso comando diz –nkv keyValueList=”amenity.school “. Pode adivinhar que isto indica que o Osmosis deve filtrar tudo o que tem a etiqueta amenity=school. –nkv é a abreviatura de –node-key-value. Este comando indica que o Osmosis deve filtrar apenas nós com as chaves e valores fornecidos na lista a seguir. Podem ser adicionados conjuntos adicionais de chave.valor colocando vírgulas entre eles. Por fim, fornecemos o nome e o formato do ficheiro de saída. Usamos a flag -wx, que é uma abreviatura de –write-xml. Note que também poderíamos usar –wb, que é a contrapartida de –rbf, se quiséssemos produzir os dados novamente no formato PBF. AvançarO número de tarefas de processamento que podem ser feitas com o Osmosis é enorme e para saber mais é melhor consultar a página Utilização pormenorizada do Osmosis Detailed Usage na wiki. Uma tarefa útil é ser capaz de dividir um grande ficheiro OSM em partes separadas, quer fornecendo retângulos, quer criando ficheiros de polígonos delimitadores. Pode obter uma base básica sobre este processo na página [Página de exemplos Osmosis] (http://wiki.openstreetmap.org/wiki/Osmosis/Examples).
Este capítulo foi útil?
Diga-nos e ajude-nos a melhorar os guias!
|