|
|
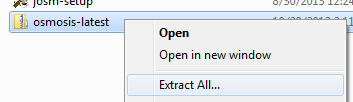
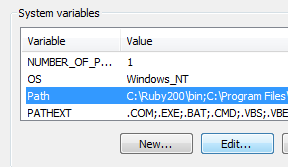
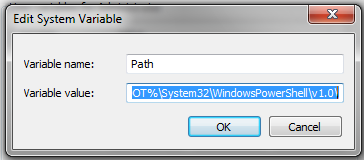
Manipulando datos con OsmosisOsmosis es una poderosa herramienta de línea de comandos para manipular y procesar datos .osm sin procesar. A menudo se usa para procesar archivos de datos grandes, para dividir archivos OSM en partes más pequeñas y para aplicar un conjunto de cambios para actualizar un archivo existente. Hay muchas funciones disponibles con Osmosis, y puedes leer sobre cada una de ellas en detalle en la Wiki. Sin embargo, muchas de las funciones son bastante complejas y difíciles de entender, especialmente si recién estás comenzando con los programas de línea de comandos y OpenStreetMap. Este capítulo servirá para presentar Osmosis, instalarlo en Windows y comenzar con un comando básico de Osmosis. Instalar OsmosisAl igual que osm2pgsql en el capítulo anterior, necesitaremos descargar y configurar osmosis para poder ejecutarlo desde la línea de comandos. El proceso para esto será muy similar a osm2pgsql. También necesitarás algunos datos OSM sin procesar para trabajar. Si deseas seguir los ejemplos de este capítulo, descarga nuestro archivo de muestra aquí. También puedes usar un archivo de datos sin procesar de tu elección. Sigue estos pasos para descargar y preparar Osmosis:
Filtrado de datosOsmosis debería funcionar correctamente desde la línea de comandos ahora. Para poder ejecutar las operaciones en nuestro archivo de datos, necesitamos cambiar el directorio de trabajo al lugar donde hemos colocado el archivo sample_osmosis.osm.pbf. Para simplificar las cosas, hemos colocado este archivo en el directorio *C:*.
Ahora aprendamos nuestro primer comando de Osmosis. Ejecutaremos un comando que filtra todas las escuelas de nuestro archivo grande. Para hacer esto, necesitamos decirle a Osmosis algunas cosas. Necesitamos especificar:
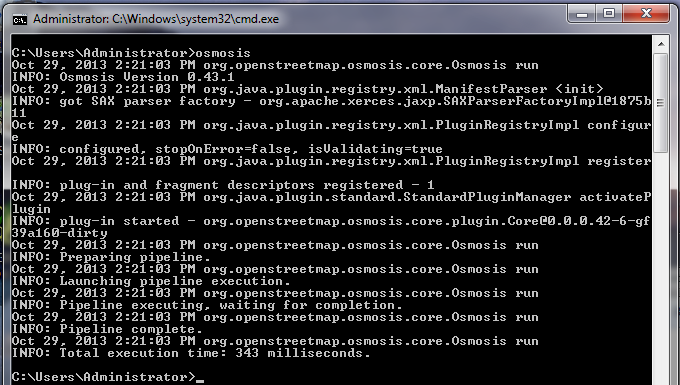
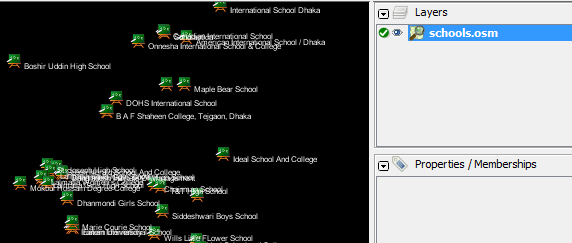
El comando que vamos a ejecutar es: Intenta ejecutar este comando en el símbolo del sistema. Cuando termine, deberías ver un nuevo archivo en tu directorio, llamado ** schools.osm **. Si abrimos el nuevo archivo en JOSM, podemos ver que solo las escuelas se han filtrado del archivo de muestra.
Echemos un vistazo al comando que ejecutamos pieza por pieza para comprender cómo funciona todo. Primero, llamamos al nombre del programa. A continuación, proporcionamos el archivo de entrada. Recuerda que este archivo está en un formato comprimido. –rbf es en realidad la abreviatura de **–read-pbf-fast **. Osmosis entiende que el archivo que proporcionamos después de este indicador es el archivo del que queremos leer. El siguiente fragmento de nuestro comando dice * - nkv keyValueList = “amenity.school” *. Puedes suponer que esto indica que la ósmosis debería filtrar todo con la etiqueta amenity=school. –nkv es la abreviatura de –node-key-value. Este comando indica que Osmosis debería filtrar solo los nodos con las claves y los valores suministrados en la siguiente lista. Además, se pueden agregar conjuntos key.value colocando comas entre ellos. Por último, proporcionamos el nombre y el formato del archivo de salida. Usamos el indicador - wx, que es la abreviatura de –write-xml. Ten en cuenta que también podríamos usar – wb, que es la contraparte de –rbf, si quisiéramos generar los datos nuevamente en formato PBF. Moviendo Hacia AdelanteEl número de tareas de procesamiento que se pueden realizar con Osmosis es enorme y, para obtener más información, es mejor consultar la página Uso detallado de Osmosis en la Wiki. Una tarea útil es poder dividir un gran archivo OSM sin procesar en partes separadas, ya sea proporcionando rectángulos o creando archivos poligonales delimitadores. Puedes obtener una base básica en este proceso en la página de ejemplos de Osmosis.
¿Fue útil este capítulo?
¡Háganos saber y ayúdenos a mejorar las guías!
|