|
|
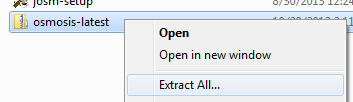
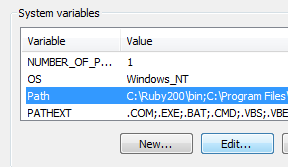
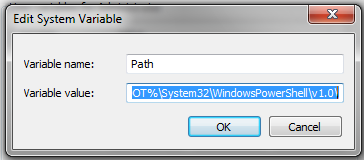
Przetwarzanie danych w OsmosisOsmosis jest potężnym narzędziem wiersza polecenia do przetwarzania surowych danych .osm. Jest ono często używane do przetwarzania wielkich plików z danymi, do dzielenia plików OSM na mniejsze kawałki i do stosowania zestawów zmian do aktualizacji istniejących plików. W Osmosis jest dostępnych wiele wspaniałych funkcji, o których możesz przeczytać szczegółowo na Wiki. Wiele funkcji jest dość skomplikowanych i trudnych do zrozumienia, zwłaszcza jeśli dopiero zaczynasz z programami konsolowymi i OpenStreetMap. Ten rozdział służy wprowadzeniu do Osmosis, instalowaniu go w Windowsie i rozpoczynaniu pracy z jego podstawowymi komendami. Instalowanie OsmosisTak, jak z osm2pgsql w poprzednim rozdziale, musimy pobrać i zainstalować osmosis, aby móc go uruchamiać z wiersza polecenia. Postępowanie będzie bardzo podobne do tego z osm2pgsql. Będziesz potrzebował również trochę surowych danych OSM do pracy. Jeżeli chcesz powtórzyć przykład z tego rozdziału, pobierz nasz przykładowy plik tutaj. Możesz również wybrać surowe dane według własnego uznania. Wykonaj następujące kroki, aby pobrać i przygotować Osmosis:
Filtrowanie danychOsmosis powinien teraz działać prawidłowo z wiersza polecenia. Aby móc pracować na naszym pliku z danymi, musimy zmienić katalog roboczy na miejsce, gdzie umieściliśmy plik sample_osmosis.osm.pbf. Dla ułatwienia, umieściliśmy ten plik w *katalogu C:*.
Nauczmy się teraz pierwszej komendy Osmosis. Uruchomimy polecenie, które odfiltruje wszystkie szkoły z naszego wielkiego pliku. Aby to zrobić, musimy powiedzieć Osmosis kilka rzeczy. Musimy określić:
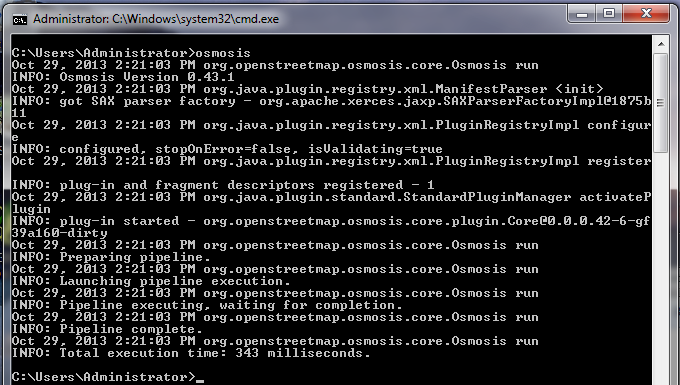
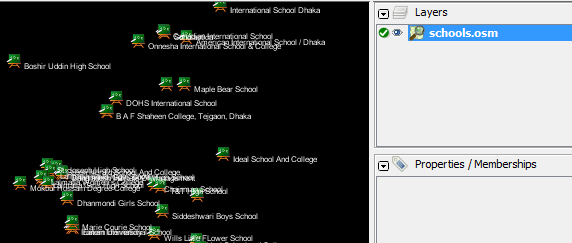
Polecenie, które uruchomimy, to: Spróbuj uruchomić tą komendę w wierszu polecenia. Kiedy zostanie ukończona, powinieneś zobaczyć nowy plik w swoim folderze, nazwany szkoly.osm. Jeżeli otworzymy ten nowy plik w JOSM, zobaczymy, że tylko szkoły zostały odfiltrowane z przykładowego pliku.
Spójrzmy na wykonane polecenie kawałek po kawałku, żeby zrozumieć, jak to wszystko działa. Najpierw wywołujemy nazwę programu. Następnie podajemy plik wejściowy. Zapamiętaj, że ten plik jest w skompresowanym formacie. –rbf jest skrótem od –read-pbf-fast. Osmosis, że plik, który wskazujemy po tym argumencie, jest plikiem, z którego chcemy czytać dane. Następny fragment naszego polecenia, to –nkv keyValueList=”amenity.school”. Możesz domyślić się, że wskazuje to osmosis, że powinien odfiltrować wszystko z tagiem amenity=school. –nkv to skrót od –node-key-value. To polecenie mówi, że Osmosis, powinien odfiltrować tylko węzły z kluczami i wartościami podanymi w dołączonej liście. Dodatkowe zestawy klucz.wartość mogą być dodane przez stawianie przecinków między nimi. Na końcu podajemy nazwę i format pliku wyjściowego. Używamy argumentu -wx, który jest skrótem od –write-xml. Zauważ, że jeśli chcemy, aby dane były ponownie w formacie PBF, możemy użyć –wb, który jest odpowiednikiem –rbf. Dalsze działaniaLiczba zadań, jakie można wykonać z Osmosis jest olbrzymia, więc, aby dowiedzieć się więcej najlepiej przejść do strony Szczegółowe wykorzystanie Osmosis na Wiki. Jednym z przydatnych zadań jest zdolność do dzielenia dużych plików z surowymi danymi OSM file na oddzielne części, zarówno przez podawanie prostokątów, jak i przez tworzenie plików z wielokątami ograniczającymi. Możesz poznać podstawy tego procesu na stronie z przykładami Osmosis.
Czy ten rozdział był pomocny?
Daj nam znać i pomóż w ulepszeniu przewodników!
|